How would you design an autocomplete for a search engine?
Type "how to" into Google. Before you finish typing, ten suggestions appear. In under 50 milliseconds. Across billions of possible queries. That's autocom...
9 Mar 2024
Type "how to" into Google. Before you finish typing, ten suggestions appear. In under 50 milliseconds. Across billions of possible queries. That's autocomplete — and it's one of the most performance-critical features in any search system.
I've built autocomplete systems that worked great at 100 queries per second and fell apart at 10,000. The lesson: autocomplete is a latency problem disguised as a search problem.
Business Requirements
- Faster Search — autocomplete reduces keystrokes. Users find what they want faster. This directly impacts engagement and satisfaction.
- Competitive Edge — a great autocomplete experience makes users prefer your search engine. A slow or irrelevant one drives them away.
- Monetization — autocomplete can surface sponsored suggestions. If users type "best laptop" and you suggest "best laptop deals at BestBuy," that's targeted advertising built into the search experience.
Technical Requirements
- Sub-50ms Latency — autocomplete fires on every keystroke. If it's slower than the user's typing speed, the suggestions feel stale and useless.
- Scalability — millions of concurrent users, each generating 5-10 keystroke events per search. That's potentially billions of autocomplete requests per day.
- Real-Time Updates — trending topics, breaking news, new products. The suggestion index must reflect the current world, not yesterday's data.
- Relevance — suggestions must be ranked by likelihood, popularity, personalization, and freshness. Showing irrelevant suggestions is worse than showing none.
Challenges
Data volume. Billions of historical queries. Millions of documents. The index must be fast to query despite its size.
Latency budget. 50ms total. That includes network round-trip, server processing, and rendering. The actual lookup needs to happen in single-digit milliseconds.
Relevance tuning. Popularity-based ranking works for most queries. But for personalized suggestions, you need per-user signals — search history, location, language, context. That's more data to process in the same latency budget.
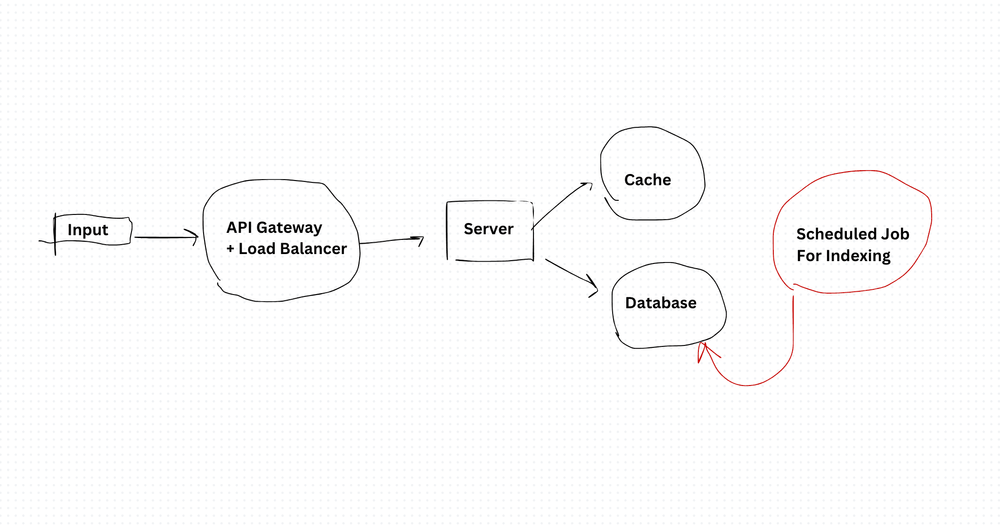
Architecture

The flow is straightforward: user types → request hits API gateway and load balancer → autocomplete service checks cache → if cache miss, queries the index → returns ranked suggestions.
The key is the index. Everything depends on how you build and query it.
How to Build the Index
Approach 1: Trie (Prefix Tree)
A trie is a tree structure where each node represents a character. All descendants of a node share a common prefix. To find suggestions for "hel," you traverse to the "h" → "e" → "l" node and return all completions below it.
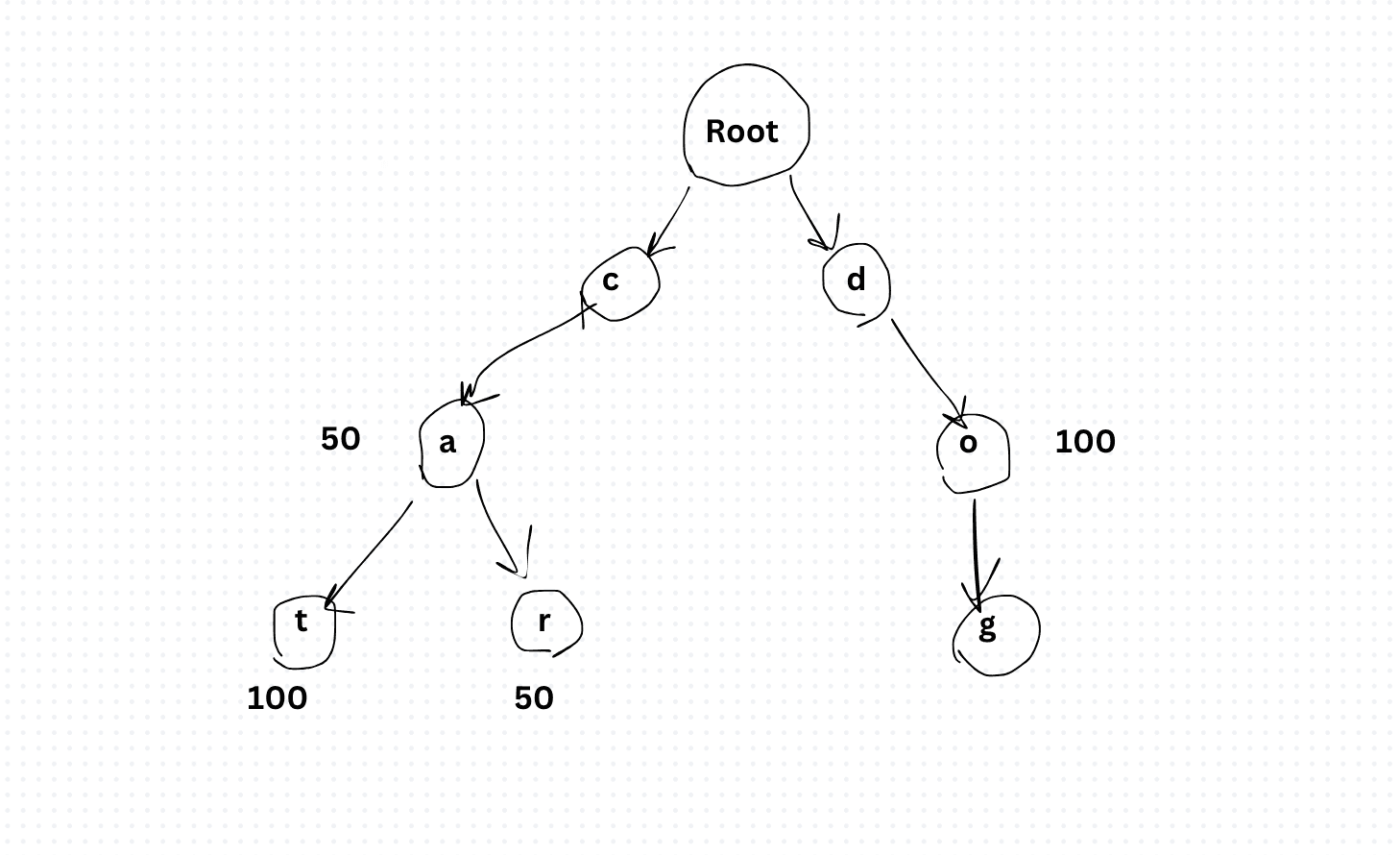
Benefit: Fast prefix lookups. O(k) where k is the prefix length. Memory-efficient with shared prefixes.
Cost: Hard to rank results by popularity without augmenting each node with scores. Updating the trie in real-time is complex. Doesn't handle typos or fuzzy matching.
Approach 2: Inverted Index
An inverted index maps each term to a list of documents (or queries) containing it. Elasticsearch uses this approach. You index historical queries, then search the index for prefix matches.
Benefit: Handles ranking naturally (TF-IDF, BM25). Supports fuzzy matching and typo correction. Battle-tested at scale (Elasticsearch powers most production search systems).
Cost: Higher latency than a trie for simple prefix lookups. More storage. More operational complexity.
Approach 3: Predictive ML Models
Train a model on historical query data to predict the most likely completions for a given prefix. This is fundamentally how large language models like ChatGPT work — predicting the next token based on context.
Benefit: Handles context and personalization naturally. Can suggest queries the user hasn't typed before. Adapts to trends automatically.
Cost: High computational cost per prediction. Latency can be problematic for real-time autocomplete. Requires significant training data and infrastructure.
The Trade-Offs
Trie vs. inverted index. Tries are faster for pure prefix matching. Inverted indexes are more flexible — they support fuzzy matching, ranking, and filtering. For a simple autocomplete, a trie is sufficient. For a full-featured search engine, go with an inverted index.
Caching vs. freshness. Cache popular prefixes aggressively ("how to," "what is," "best"). But trending queries need to appear quickly, which means shorter TTLs for some cache entries. I use a tiered cache: long TTL for stable prefixes, short TTL for trending ones.
Personalization vs. privacy. Personalized suggestions require storing user search history. That's powerful for relevance but raises privacy concerns. Offer users control: let them opt out or clear their history.
Latency vs. relevance. More sophisticated ranking (ML models, personalization) produces better suggestions but takes longer. Simple popularity-based ranking is fast but generic. Most production systems use a hybrid: fast prefix lookup with lightweight re-ranking.
The best autocomplete systems are invisible. Users don't notice them working — they just notice when they're missing.
From Senior to Staff: Master the Architecture Skills That Get You Promoted
Go from shaky in design reviews to the engineer everyone trusts to architect the hard stuff.
View the live cohortKeep reading
- Everything Is Being Rewritten in Rust. Is It Time You Learned It?
- The Capacity Estimation Numbers Every Engineer Should Carry Into a System Design
- Notes From My First Cohort: System Design Is Trade-offs, Not Answers
- Write HLDs and ADRs in HTML or React, Not Markdown
- CRDTs: Conflict-Free Merging in Distributed Systems
- Race Conditions: What They Are and How to Handle Them